最近在忙的项目有个比较棘手的数据同步程序,做了好长一段时间,碰到的挑战不少,简单记录一下。首先看需求:
- 由于数据统计要求,需要将某数据系统里的多个服务系统的数据同步到本地数据库中,同步的时间周期为一年开始到最新的数据。
- 该系统中的数据条目基本上每天都可能有数万条更新,且今天同步完的数据第二天仍然可能会发生改变。
- 某个服务在该系统中并不是每一天都有数据,可能某些天有数据,某些天没有数据。
- 数据同步程序采用微服务方式部署,具体表现形式为一个 Docker Instance,这意味着这个程序可能会经常重启或者部署。
- 数据同步程序需要做到无人值守,且能够正确同步所需要处理的数据,不可以有遗漏,且可以同步到最新的状态。
实现时最容易想到的策略自然是简单粗暴的:写一个程序将所有数据通过对方系统提供的 API 加载上来,对其中的数据一条一条进行同步。但这个想法显然不可取,首先是目标系统里的数据量本身就有上千万条,无法一次性加载,其次本系统仍然需要定期更新重启,重启服务以后仍然重新加载所有数据效率更低。所以,设计了以下几个策略:
- 对于一个服务的数据,一次只加载7天的数据,将加载到的数据经过转换后记录在数据库中,保留记录的创建时间。
- 使用目标系统的 API 对数据进行分页读取,以减少数据传输的压力。
- 采用一个调度程序来对该数据同步程序进行调度,每两小时运行一次。调度程序启动数据同步程序时需检查同步程序状态,如果同步程序正在运行,则不重复运行,等待下次一次调度。
- 每次同步一个服务的数据首先检查上一次同步的数据,获取最后同步到数据的更新时间,针对目标系统的数据最新数据在一天内可能发生变化的情况,将继续读取的时间设置为最后的数据更新时间减一天,从而保证这一天的数据可以再次被刷新。如果在系统中没有已知同步数据,则使用一年前的时间作为起始时间。
- 一次同步一个服务的7天的数据,或者如果该时间窗口内没有数据,则继续将时间窗口以7天为单位向前推进,直到时间窗口超过现在时间。
- 在调试期间,使用单线程作业,同步程序稳定后使用多线程(线程池)进行同步。
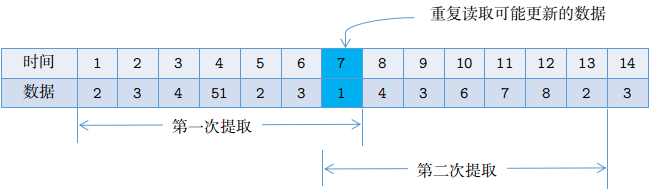
图1:最初的时间窗口滑动设计
在调试的过程中发现,上述看上去比较严谨的策略其实存在一个逻辑漏洞。这主要是针对需求:某个服务在该系统中并不是每一天都有数据,可能某些天有数据,某些天没有数据。由于我们需要刷新可能发生的变动,因此重新启动数据同步程序之后起始同步的时间为最新的数据的创建时间减1,然后以这个时间点一次装载7天的数据,运行完这批数据之后直接去抓取一下个服务的数据。这里存在一种情况:注意这个时间窗口获取到的数据仅仅是时间窗口的第一天的数据,即我们上一次加载的最后一天的数据,此后六天都没有数据,由于上述策略一次启动只处理这一批数据,则上述策略会形成一个死循环,每次都只加载最后那一部分数据,而不会向前推进。如下图所示:
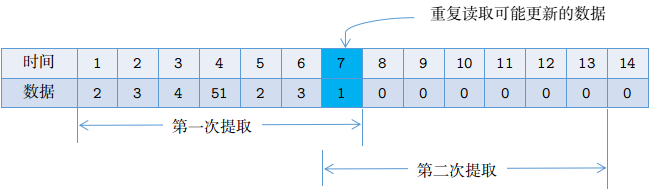
图2:时间窗口滑动设计存在的缺陷
因此,将数据同步的策略改进得更贪婪一些,每次必须读取两个时间的数据,改进如下:
- 将同步的数据改成加载两个批次,第一个批次的时间窗口为:(最后更新的数据时间 – 1) + 7
- 不管上一个时间窗口内是否加载到数据,继续下移一个时间窗口,再加载一次数据,直到加载到最新的数据,或者时间窗口超过现在时间。
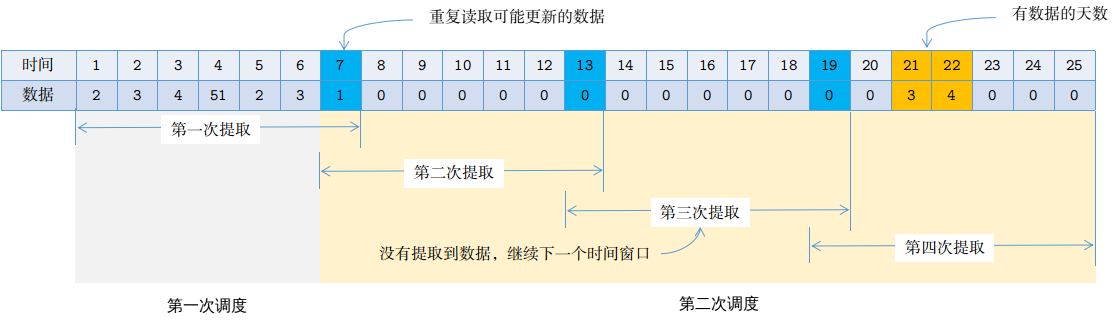
图3:改进后的时间窗口滑动策略
通过这个简单的策略改进,使得在下一次同步时时间窗口能够往前滑动至少7天。在上图的例子中,提取数据的场景从第二次调度时开始,这次只处理了第7天的数据,这时会继续尝试读取新的一个时间窗口的数据,第三次读取时发现没有数据,再将窗口滑动一个周期,进行第四次尝试,直到这次读取到数据。
在并发方面,一开始的时候将并发线程的实现放在了服务级别,即使用一个线程专门处理一个服务,该线程在处理过程中会处理多条记录,这一部分后来也进行了改进,将线程处理的单元改成数据记录,使用线程池处理提取出的记录,服务是按顺序执行的。这样处理最大程度减少了不同服务配置了相同数据源的并发问题,同时在监控日志的输出上,由于线程池处理的是同一个服务就近的记录,可读性也好很多。这里多说一点的是,在这种数据同步程序的处理能力来看,并发数量并不是越多越好,因为目标系统是一个不断产生数据,更新数据的生产系统,通过 API 来对外进行服务,数据同步程序应当尽量在提高数据处理能力的同时,需要减少对目标系统的压力,从而保证目标系统的稳定性和服务能力,而且这一点很重要。如果目标系统是一个支持超高并发的系统,那么我们后续的改进空间可以考虑利用集群来处理原子记录,将提取的原子记录分别分发到一个分布式消息队列里,然后使用多个节点的集群对消息队列里的记录进行处理,并发能力几乎是可以线性扩展的。
以上只是数据同步程序的最简单粗暴的一种实现,相信数据同步的方式和策略绝对不止一种,实现时需要具体问题具体分析并不断优化才能获得较完美的方案。
我是你家 电子日记本 的忠实客户,同样是1999年出道开始写代码,幸会
李志您好,电子日记本是我好友郝新庚先生的作品。谢谢你对电子日记本的支持。你可以在 http://haoxg.net/ 找到电子日记本和作者的相关信息。平时比较忙,更新较少,但也欢迎访问我的博客交流。谢谢~